
After blogging last week about use of journal impact factors in REF2014, many people have asked me what alternative I'd recommend. Clearly, we need a transparent, fair and cost-effective method for distributing funding to universities to support research. Those designing the REF have tried hard over the years to devise such a method, and have explored various alternatives, but the current system leaves much to be desired.
Consider the current criteria for rating research outputs, designed by someone with a true flair for ambiguity:
| Rating | Definition |
|---|---|
| 4* | Quality that is world-leading in terms of originality, significance and rigour |
| 3* | Quality that is internationally excellent in terms of originality, significance and rigour but which falls short of the highest standards of excellence |
| 2* | Quality that is recognised internationally in terms of originality, significance and rigour |
| 1* | Quality that is recognised nationally in terms of originality, significance and rigour |
Since only 4* and 3* outputs will feature in the funding formula, then a great deal hinges on whether research is deemed “world-leading”, “internationally excellent” or “internationally recognised”. This is hardly transparent or objective. That’s one reason why many institutions want to translate these star ratings into journal impact factors. But substituting a discredited, objective criterion for a subjective criterion is not a solution.
The use of bibliometrics was considered but rejected in the past. My suggestion is that we should reconsider this idea, but in a new version. A few months ago, I blogged about how university rankings in the previous assessment exercise (RAE) related to grant income and citation rates for outputs. Instead of looking at citations for individual researchers, I used Web of Science to compute an H-index for the period 2000-2007 for each department, by using the ‘address’ field to search. As noted in my original post, I did this fairly hastily and the method can get problematic in cases where a Unit of Assessment does not correspond neatly to a single department. The H-index reflected all research outputs of everyone at that address – regardless of whether they were still at the institution or entered for the RAE. Despite these limitations, the resulting H-index predicted the RAE results remarkably well, as seen in the scatterplot below, which shows H-index in relation to the funding level following from RAE. This is computed by number of full-time staff equivalents multiplied by the formula:
.1 x 2* + .3 x 3* + .7 x 4*
(N.B. I ignored subject weighting, so units are arbitrary).
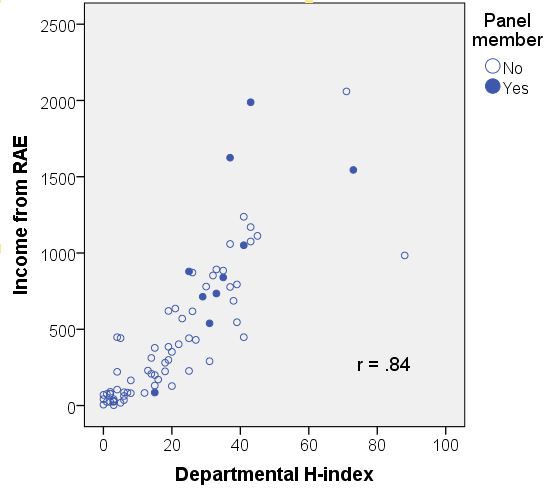 |
| Psychology (Unit of Assessment 44), RAE2008 outcome by H-index |
Yes, you might say, but the prediction is less successful at the top end of the scale, and this could mean that the RAE panels incorporated factors that aren’t readily measured by such a crude score as H-index. Possibly true, but how do we know those factors are fair and objective? In this dataset, one variable that accounted for additional variance in outcome, over and above departmental H-index, was whether the department had a representative on the psychology panel: if they did, then the trend was for the department to have a higher ranking than that predicted from the H-index. With panel membership included in the regression, the correlation (r) increased significantly from .84 to .86, t = 2.82, p = .006. It makes sense that if you are a member of a panel, you will be much more clued up than other people about how the whole process works, and you can use this information to ensure your department’s submission is strategically optimal. I should stress that this was a small effect, and I did not see it in a handful of other disciplines that I looked at, so it could be a fluke. Nevertheless, with the best intentions in the world, the current system can’t ever defend completely against such biases.
So overall, my conclusion is that we might be better off using a bibliometric measure such as a departmental H-index to rank departments. It is crude and imperfect, and I suspect it would not work for all disciplines – especially those in the humanities. It relies solely on citations, and it's debatable whether that is desirable. But for sciences, it seems to be pretty much measuring whatever the RAE was measuring, and it would seem to be the lesser of various possible evils, with a number of advantages compared to the current system. It is transparent and objective, it would not require departments to decide who they do and don’t enter for the assessment, and most importantly, it wins hands down on cost-effectiveness. If we'd used this method instead of the RAE, a small team of analysts armed with Web of Science should be able to derive the necessary data in a couple of weeks to give outcomes that are virtually identical to those of the RAE. The money saved both by HEFCE and individual universities could be ploughed back into research. Of course, people will attempt to manipulate whatever criterion is adopted, but this one might be less easily gamed than some others, especially if self-citations from the same institution are excluded.
It will be interesting to see how well this method predicts RAE outcomes in other subjects, and whether it can also predict results from the REF2014, where the newly-introduced “impact statement” is intended to incorporate a new dimension into assessment.
No comments:
Post a Comment